A summary of git data model and commonly used commands.
Data model
Git is created by Linus to manage the Linux repository, so it’s designed for efficient repository changes tracking and version restoring and branch merging, etc.
Now, thinking as the creator, what should we consider to properly manage a repository? I’ll say that includes file, directory, and modification.
In git, the data model of these structures are as follows.1
2
3
4
5
6
7
8
9
10
11
12
13// a file is a bunch of bytes
type blob = array<byte>
// a directory contains named files and directories
type tree = map<string, tree | file>
// a commit has parents, metadata, and the top-level tree
type commit = struct {
parent: array<commit>
author: string
message: string
snapshot: tree
}
A snapshot is the top-level tree that is being tracked. In the below example, a snapshot could be a tracked version of the root tree. And a commit contains not only the snapshot at this version but the parent commit, author, and message.
Now, it’s easy to image how these models can represent the whole structure, dependencies, modifications of a repository.
1 | <root> (tree) |
In fact, a git history is a directed acyclic graph (DAG) of commits. Visualizing a commit history might look something like this:1
2
3
4o <-- o <-- o <-- o
^
\
--- o <-- o
where each “o”, i.e. commit, is pointing to its parent commit (the older commit). After the third commit, the history branches into two separate branches. This might correspond to, for example, two separate features being developed in parallel, independently from each other.
Objects and content-addressing
In Git data store, Blobs, trees, and commits are unified in this way: they are all objects. All objects are content-addressed by their SHA-1 hash (i.e. a hashed string with 40 characters). When they reference other objects, they don’t actually contain them in their on-disk representation, but have a reference to them by their hash.1
2type object = blob | tree | commit
objects = map<string, object>
You can easily image this using the idea of pointer references, the only difference is that git uses the hashed values for addressing the content.
Since git uses content addressable storage, it means that commits in Git are immutable. This doesn’t mean that mistakes can’t be corrected, however; it’s just that “edits” to the commit history are actually creating entirely new commits.
References
Now, all snapshots can be identified by their SHA-1 hash. That’s inconvenient, because humans aren’t good at remembering strings of 40 hexadecimal characters.
Solution to this problem is human-readable names for SHA-1 hashes, called “references”. References are pointers to commits. Unlike objects, which are immutable, references are mutable (can be updated to point to a new commit). For example, the master reference usually points to the latest commit in the main branch of development.
1 | references = map<string, string> |
With this, Git can use human-readable names like “master” to refer to a particular snapshot in the history, instead of a long hexadecimal string.
One detail is that we often want a notion of “where we currently are” in the history, so that when we take a new snapshot, we know what it is relative to (how we set the parents field of the commit). In Git, that “where we currently are” is a special reference called “HEAD”.
Repositories
Finally, we can define what (roughly) is a Git repository: it is the data objects and references.
On disk, all Git stores are objects and references: that’s all there is to Git’s data model. All git commands map to some manipulation of the commit DAG by adding objects and adding/updating references.
Whenever you’re typing in any command, think about what manipulation the command is making to the underlying graph data structure.
Staging area
One more thing to mention is that, imaging a scenario where you have print logs in your repository; you want to commit the code while discarding all the logs.
Git accommodates such scenarios by allowing you to specify which modifications should be included in the next snapshot through a mechanism called the “staging area”.
Commands
Now let’s see some commonly used git commands. Before we get started, we should be able to relate the following figure with the concepts we discussed above, so that it’ll be easy to understand and memorize the git commands.
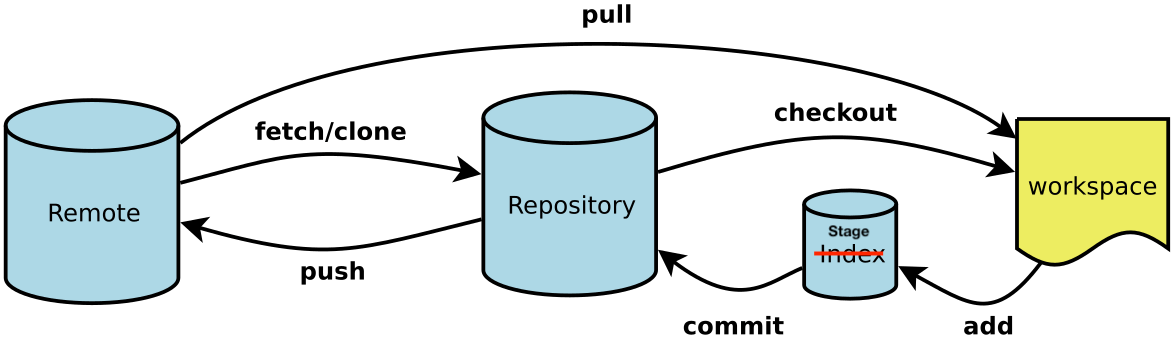
Basics
git init: creates a new git repo, with data stored in the .git directorygit status: tells you what’s going ongit add <filename>: adds files to staging areagit commit: creates a new commitgit log --all --graph --decorate: visualizes history as a DAGgit diff <filename>: show differences since the last commitgit diff <revision> <revision> <filename>: shows differences in a file between snapshots
Undo, Checkout and Reset
The status of git files is as follows.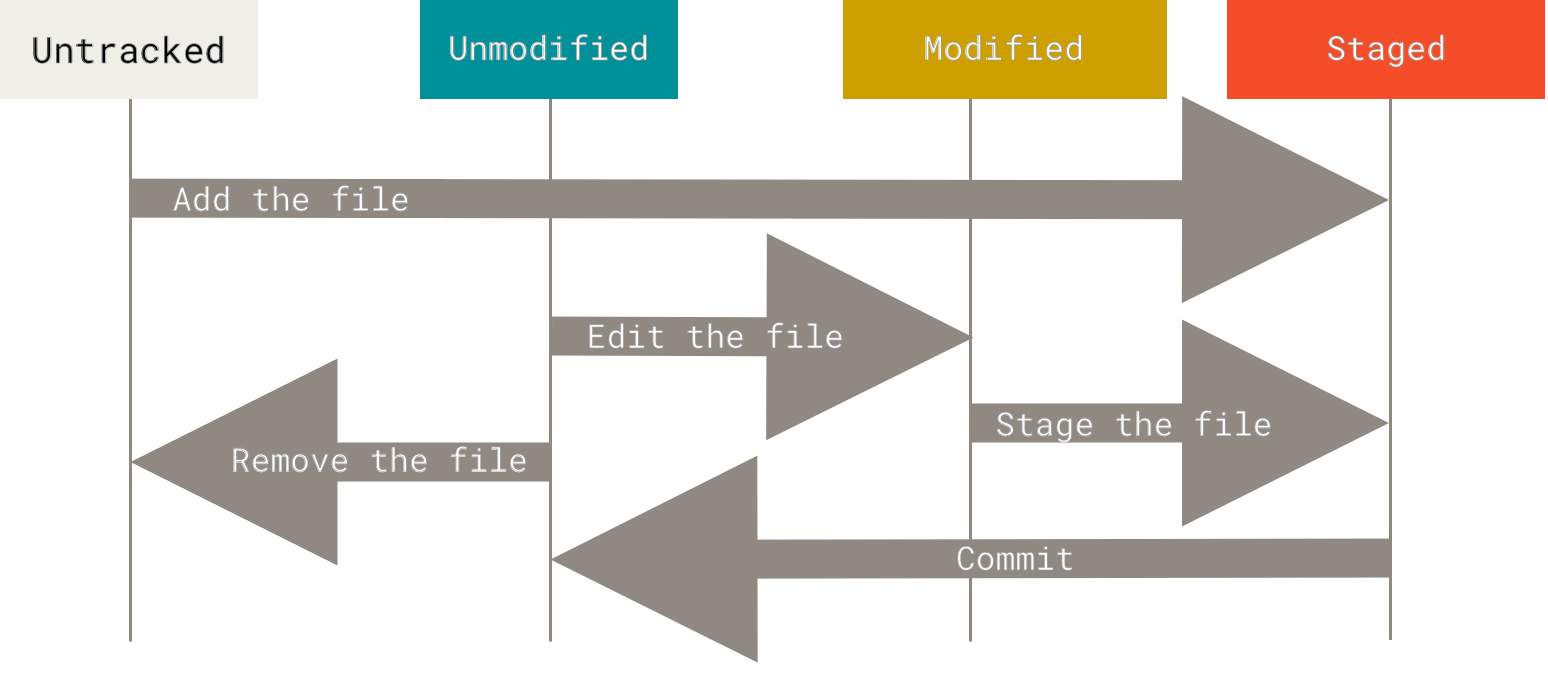
git commit --amend: lets you combine staged changes with the previous commit instead of creating an entirely new commit. It can also be used to simply edit the previous commit message without changing its snapshot (creating a new one).git checkout: Updates files in the working tree to match the version in the index or the specified tree. If nopathspecwas given, it will also update HEAD to set the specified branch as the current branch.git checkout <revision>: nopathspec, updates HEAD and current branchgit checkout <--> <file>: restore a file only to the workspace from the staging areagit checkout <commit> <file>: restore a file to workspace and the staging area using thecommitversion in repository.
git reset: Reset the HEAD of current branch to the specified state.- For HEAD:
git reset <--soft | --mixed [-N] | --hard | --merge | --keep>: see the following table. - For files:
git reset <commit> <file>: unstage a file, i.e, copy entries from<commit>to the staging area.
- For HEAD:
To differentiate
resetandcheckout, check the following table.1
2
3
4
5
6
7
8
9
10head stage work dir wd safe
Commit Level
reset --soft [commit] REF NO NO YES
reset [commit] REF YES NO YES
reset --hard [commit] REF YES YES NO
checkout [commit] YES YES NO YES
File Level
reset (commit) [file] NO YES NO YES
checkout (commit) [file] NO YES YES NONote that reset will change the Reference values (REF) in HEAD, while checkout only load a new value to HEAD, which can be visualized as follows.
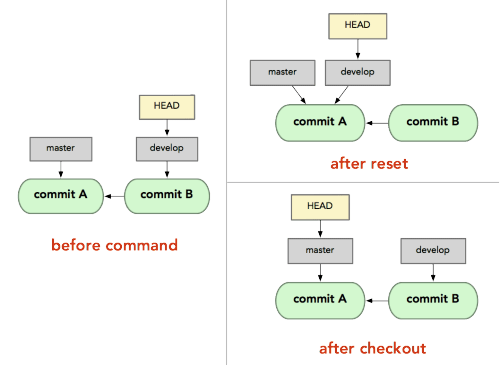
- If we need to restore a file or the entire repository to a specific version, we can use
checkout [commit] .so that we load the target content to the stage and the work dir, and HEAD won’t be changed. Instead,reset [commit] .won’t do anything to the work dir. - But if we want to discard all commits after
[commit], we should usereset --hard [commit]sincecheckoutwill load HEAD as that commit. git stashandgit stash pop: temporarily remove modifications to working directorygit revert <commit>: undo the changes of the[commit]in HEAD and create a new commit.git restore <file>: by default, load content from the staging area in HEAD.
Remote
git remote: list remotesgit remote add <name> <url>: add a remotegit push <remote> <local branch>:<remote branch>: send objects to remote, and update remote referencegit branch --set-upstream-to=<remote>/<remote branch>: set up correspondence between local and remote branchgit branch -u o/master foo: will set the foo branch to track o/master.git fetch <remote> <remote branch>:<local branch>: retrieve objects/references from a remote branch, it doesn’t require HEAD to be on target<commit>, and it doesn’t update your local non-remote branches. If no branch specified, fetch all the branches.git pull <remote> <remote branch>:<local branch>: During a pull operation, commits are downloaded onto o/master and then merged into the current branch. It basically afetchand amerge.git clone: download repository from remote
Branching and merging
git branch: shows branchesgit branch <name>: creates a branchgit checkout -b <name>: creates a branch and switches to itgit merge <revision>: merges<revision>into current branchgit merge --abort: abort a merge.git mergetool: use a fancy tool to help resolve merge conflictsgit rebase <to-branch> <from-branch>: rebase set of patches of<from-branch>onto a new base, i.e.<to-branch>. If your master branch isA-B-C, and you do rebase to master on another branch:A-B-D, the HEAD will be set to master branch, and now master branch isA-B-C-D. It also can be used to combine a few commits to one commit before merging, so that we won’t have to much separate information. Another adv of rebase is that it can simplify the process of merging. This Chinese post is very helpful to understandrebase.
Advanced Git
git config: Git is highly customizablegit clone --shallow: clone without entire version historygit add -p: interactive staginggit rebase -i: interactive rebasinggit blame: show who last edited which linegit bisect: binary search history (e.g. for regressions)git tag [commit]: Create a tag on [commit], it is permanent, unlike branches. If you leave the commit off, git will just use whatever HEAD is atgit describe <ref>: tell you where you are relative to the closest “anchor” (aka tag).gitignore: specify intentionally untracked files to ignore
Miscellaneous
- Use relative ref: the first parent of C1:
C1^, the second parent:C1^2,the parent of C1’s parent:C1^^, find the xth ancestor of C1:C1~x. git branch -f [branch] [commit], git reset [commit] (current branch): move the point of a branch to a specific commitgit checkout [commit]: use this command to set HEAD to commits (not branch)git cherry-pick [commits]: replicate commits under current HEAD.
Summary
The following figure visualizes commonly used git commands.
Resources
- The text of this post is largely based on MIT The missing semester, RuanYifeng Blog, chanjarster post.
- Two exercises are recommended: git-game, branching game.
- Visualize Git